Резервное копирование и восстановление БД
Contents
Резервное копирование и восстановление БД#
Для организации бекапа базы мы рекомендуем локальное снятие дампа. Это происходит быстрее, не грузит сеть. Администратор должен следить за свободным местом на диске, свободного места должно хватать для снятия дампа. Лучше всего для сохранения дампа использовать отдельный том. Это позволяет избежать аварийной остановки постгреса при нехватке места на диске.
Локально снятый дамп архивируется и помещается на внешнее NAS хранилище.
Возможно применение сторонних средств резервного копирования, таких как Кибер Бэкап для PostgreSQL
Снятие дампа#
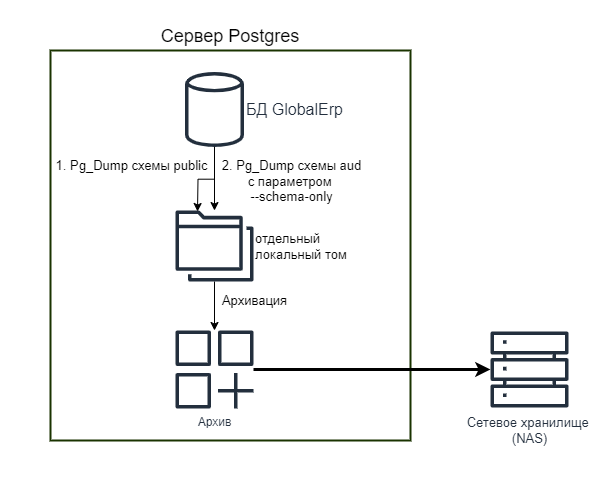
Снятие дампа выполняется штатной утилитой pg_dump
Для бекапа снимаем только схему public, ее достаточно для сохранения всех данных системы. Отдельно снимаем структуру всех объектов схемы aud. Это позволяет при восстановлении не пересоздавать структуры хранения аудита из системы Global.
Если требуется сохранить аудит, то схему aud рекомендуется снимать отдельно.
Совет
При включенном аудите в системе Global и высокой интенсивности работы схема aud может содержать большие объемы данных (Несколько терабайт). Создание резервной копии схемы aud может занимать продолжительное время.
Обычно все схемы снимаются для переустановки PostgreSQL или обновления версии PostgreSQL, с последующим нагоном полного дампа.
Для снятия дампа используйте формат «Директория». Это позволяет снимать дамп в многопоточном режиме и существенно ускоряет процесс.
Общий пример запуска утилиты снятия дампа
${sDumpUtl} -F d --dbname=postgresql://${sUser}:${sPass}@${sHost}:5432/${sDbName} --jobs=$nColDbJobs --schema=public --blobs --verbose
где
${sDumpUtl} - путь к утилите pg_dump
${sUser} - логин
${sPass} - пароль
${sHost} - хост
${sDbName} - имя бд
$nColDbJobs - количество потоков (выставляется по количеству ядер на сервере postgresql)
Общий пример запуска утилиты для снятия схемы aud без данных
${sDumpUtl} -F d --dbname=postgresql://${sUser}:${sPass}@${sHost}:5432/${sDbName} --jobs=$nColDbJobs --schema=aud --schema-only --blobs --verbose --file=$sOutputDumpDir
где
${sDumpUtl} - путь к утилите pg_dump
${sUser} - логин
${sPass} - пароль
${sHost} - хост
${sDbName} - имя бд
$nColDbJobs - количество потоков (выставляется по количеству ядер на сервере postgresql)
Совет
Параметр --schema-only позволяет выгружать только определения объектов (схемы), без данных.
После снятия дампа запаковываем директорию архиватором tar
tar -cvf ${sArchiveDir}/${sTarFileName} $sOutputDumpDir
где
${sArchiveDir} - директория для архива
${sTarFileName} - имя архивного файла
$sOutputDumpDir - директория с дампом
Развертывание дампа#
Развертывание дампа выполняет штатная утилита pg_restore
Перед развертыванием дампа обязательно удаляем все объекты схемы public
$psqlUtl postgresql://${sUser}:${sPass}@${sHost}:5432/${sDbName} -f $SCRIPTPATH/drop.sql
где
${psqlUtl} - путь к утилите psql
${sUser} - логин
${sPass} - пароль
${sHost} - хост
${sDbName} - имя бд
$SCRIPTPATH - путь до файла drop.sql
файл drop.sql
SET search_path TO public;
--
DO $$ DECLARE
r RECORD;
BEGIN
FOR r IN (SELECT p.oid::regprocedure as sFunctionName
FROM pg_proc p
INNER JOIN pg_namespace ns ON (p.pronamespace = ns.oid)
inner join pg_roles a on p.proowner =a.oid
WHERE ns.nspname = current_schema
and a.rolname =current_user
and p.probin is null) LOOP
EXECUTE 'DROP FUNCTION IF EXISTS ' || r.sFunctionName || ' CASCADE';
commit;
END LOOP;
END $$;
--
DO $$ DECLARE
r RECORD;
BEGIN
FOR r IN (SELECT tablename FROM pg_tables WHERE schemaname = current_schema()) LOOP
EXECUTE 'DROP TABLE IF EXISTS ' || quote_ident(r.tablename) || ' CASCADE';
commit;
END LOOP;
END $$;
--
DO $$ DECLARE
r RECORD;
BEGIN
FOR r IN (SELECT c.relname
FROM pg_class c
inner join pg_catalog.pg_namespace n on c.relnamespace =n.oid
inner join pg_roles a on c.relowner =a.oid
WHERE (c.relkind = 'S')
and n.nspname =current_schema
and a.rolname =current_user) LOOP
EXECUTE 'drop sequence IF EXISTS ' || quote_ident(r.relname) || ' CASCADE';
commit;
END LOOP;
END $$;
--
DO $$ DECLARE
r RECORD;
BEGIN
FOR r IN (SELECT c.relname
FROM pg_class c
inner join pg_catalog.pg_namespace n on c.relnamespace =n.oid
inner join pg_roles a on c.relowner =a.oid
where c.relkind ='v'
and n.nspname =current_schema
and a.rolname =current_user) LOOP
EXECUTE 'drop view IF EXISTS ' || quote_ident(r.relname) || ' CASCADE';
commit;
END LOOP;
END $$;
--
SELECT lo_unlink(l.oid)
FROM pg_largeobject_metadata l
inner join pg_roles a on l.lomowner =a.oid
WHERE a.rolname =current_user;
Перед развертыванием дампа его нужно распаковать
tar -xvf ${dumpArchiveFile} -C $sTempPath
запустите утилиту развертывания дампа
$sRestoreUtl --dbname=postgresql://${sUser}:${sPass}@${sHost}:5432/${sDbName} -O -x -v --no-tablespaces --jobs=$nColDbJobs $sRealDumpDir
где
$sRestoreUtl - путь к утилите pg_restore
${sUser} - логин
${sPass} - пароль
${sHost} - хост
${sDbName} - имя бд
$nColDbJobs - количество потоков (выставляется по количеству ядер на сервере postgresql)
$sRealDumpDir - путь к каталогу с файлами дампа