Мониторинг кластера Global ERP#
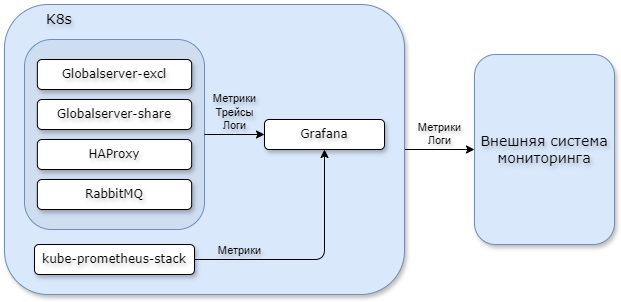
Кластер Global ERP собирает следующую телеметрию:
Метрики с использованием стека kube-prometheus-stack + Opentelemetry Collector + Prometheus.
Трейсы пользовательских операций с использованием стека Opentelemetry Collector + Tempo.
Логи с использованием стека Promtail + Loki.
Вся телеметрия собирается во внутренние инстансы Prometheus, Loki и Tempo, которые запущены в поде grafana. Внутренняя Grafana используется для оперативного мониторинга системы, так как данные удаляются при перезапуске пода.
Для долгосрочного хранения телеметрии требуется отдельная внешняя система мониторинга.

Логи#
Логи планировщика заданий, серверов Global и HAProxy обрабатываются агентом Promtail и отсылаются в базу Loki.
Также возможно настроить отправку логов во внешний инстанс Loki или отправку логов напрямую из Logback Globalserver-a.
Внешний инстанс Loki#
Для отправки логов во внешний инстанс Loki при конфигурировании групп ресурсов и книг ресурсов кластера Global в поле «Дополнительно отсылать метрики во внешнюю систему» требуется выставить «Да» и задать корректный адрес внешнего инстанса Loki.
Loki устанавливается по официальной документации.
Простейший конфиг приведён ниже. При его использовании требуется задать корректные значения параметров path_prefix, chunks_directory и rules_directory.
Пример config.yaml
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
common:
instance_addr: 127.0.0.1
path_prefix: <path> #/mnt/data/loki
storage:
filesystem:
chunks_directory: <path> #/mnt/data/loki/chunks
rules_directory: <path> #/mnt/data/loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h
ruler:
alertmanager_url: http://localhost:9093
analytics:
reporting_enabled: false
Отправка логов из Logback#
Для отправки логов во внешнюю систему напрямую из Logback Globalserver-а в профиль аппкита по пути profile\globalserver\template\config требуется добавить дополнительные файлы конфигурации:
logback-LoggerContext-ext.xml- дополнительная конфигурация логгера «system».logback-LoggerContext-session-ext.xml- дополнительная конфигурация логгеров «app» и «session».
Метрики#
Телеметрия Globalserver-а через Opentelemetry Collector отправляется во внутренний Prometheus.
Системная телеметрия кластера k8s собирается с помощью kube-prometheus-stack (требует отдельной установки).
Также возможно настроить внешний инстанс Prometheus на получение метрик из внутреннего инстанса.
kube-prometheus-stack в собственном кластере k8s#
При разворачивании кластера Global ERP в собственном кластере k8s требуется требуется установить kube-prometheus-stack по официальной документации
kube-prometheus-stack в VK Cloud#
При разворачивании кластера Global ERP в VK Cloud требуется установить аддон «kube-prometheus-stack» из панели управления кластером. В конфигурации аддона для компонента prometheus-node-exporter требуется добавить блок «extraArgs» для получения телеметрии ФС нод кластера.
prometheus-node-exporter:
image:
repository: "prometheus/node-exporter"
tag: v1.7.0
namespaceOverride: "monitoring"
resources:
limits:
cpu: 200m
memory: 50Mi
requests:
cpu: 100m
memory: 30Mi
extraArgs:
- --collector.filesystem
- --collector.filesystem.mount-points-exclude=^/(dev|proc|sys|var/lib/docker/.+|var/lib/kubelet/.+)($|/)
- --collector.filesystem.fs-types-exclude=^(autofs|binfmt_misc|bpf|cgroup2?|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|iso9660|mqueue|nsfs|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|selinuxfs|squashfs|sysfs|tracefs)$
Настройка внешнего Prometheus#
Prometheus устанавливается по официальной документации. Для получения метрик сервера Global Prometheus настраивается на сбор метрик с внутреннего инстанса через федерацию.
Пример config.yaml
global:
scrape_interval: 5s
evaluation_interval: 5s
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{__name__=~"^[^go_].+"}'
static_configs:
- targets:
- '<prometheus_external_ip>:9090'
Настройка внешнего инстанса Grafana#
Grafana устанавливается и настраивается по официальной документации.