Руководство по установке сервера мониторинга#
Общие сведения#
Для предотвращения перегрузки основного сервера приложений все инструменты телеметрии рекомендуется размещать на отдельной виртуальной машине.
Руководство описывает процесс установки и базовой настройки следующих компонентов:
Grafana - платформа визуализации данных;
Prometheus - система сбора и хранения метрик;
Loki - система централизованного хранения логов;
Promtail - агент для отправки логов в Loki;
OpenTelemetry Collector - компонент для сбора и экспорта телеметрических данных;
Настройки сервисов:
HAProxy;
NFS;
Global3;
GlobalScheduler.
Настройки экспортеров:
Скрипт снятия дополнительных метрик.
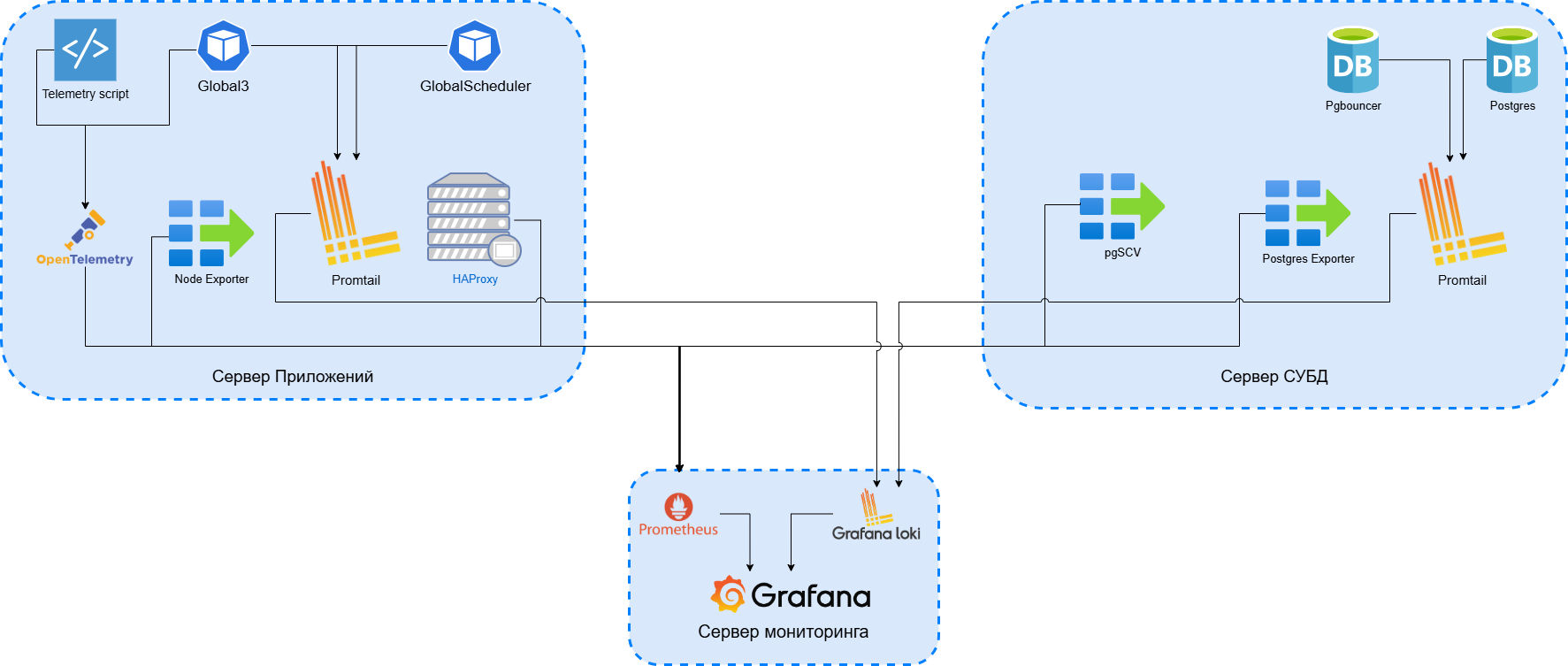
Пример архитектуры серверов#
Сервер СУБД (PostgreSQL).
Сервер приложений (Global ERP) + HAProxy (Load Balancer).
Сервер мониторинга (Prometheus, Grafana, Loki).
Принципиальная схема работы системы мониторинга:
Установка Prometheus#
Общие сведения#
Внимание
Сервис устанавливается на сервер мониторинга.
Подробная документация: Prometheus - First Steps
Загрузить релиз можно с официального сайта: prometheus.io/download
Важно
Для систем на базе Debian рекомендуется использовать установку через apt, а не скачивать последнюю версию вручную - это повышает стабильность и предсказуемость обновлений.
Установка#
sudo apt update
sudo apt install prometheus
В сервисе prometheus.service приведите стартовый параметр к следующему виду:
ExecStart=/usr/bin/prometheus $ARGS --web.enable-remote-write-receiver
Конфигурация#
Отредактируйте основной файл конфигурации: /etc/prometheus/prometheus.yml.
Пример рекомендуемой конфигурации
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
monitor: 'example'
alerting:
alertmanagers:
- static_configs:
- targets: [ 'localhost:9093' ]
rule_files:
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
scrape_timeout: 5s
static_configs:
- targets: [ 'localhost:9090' ]
relabel_configs:
- replacement: '{{project_name}}'
target_label: project_name
- job_name: 'haproxy'
static_configs:
- targets: [ '<IP адрес сервера haproxy>:8405' ]
labels: { host: '<IP адрес сервера haproxy>' }
params:
extra-counters: [ "on" ]
- job_name: 'otelcol'
static_configs:
- targets: [ '<IP адрес сервера приложений>:8888' ]
labels: { host: '<IP адрес сервера приложений>' }
relabel_configs:
- replacement: '{{project_name}}'
target_label: project_name
- job_name: 'node-exporter-global'
static_configs:
- targets: [ '<IP адрес сервера приложений>:9100' ]
labels: { host: '<IP адрес сервера приложений>' }
- job_name: 'node-exporter-postgres'
static_configs:
- targets: [ '<IP адрес сервера СУБД>:9100' ]
labels: { host: '<IP адрес сервера СУБД>' }
- job_name: 'postgres'
static_configs:
- targets: [ "<IP адрес сервера СУБД>:9187" ]
labels: { host: '<IP адрес сервера СУБД>' }
- job_name: 'pgbouncer'
static_configs:
- targets: [ "<IP адрес сервера СУБД>:9890" ]
labels: { host: '<IP адрес сервера СУБД>' }
Веб-интерфейс#
Prometheus доступен по адресу:
http://<IP_ADDRESS>:9090
где <IP_ADDRESS> - IP-адрес сервера мониторинга.
Установка Grafana#
Установка#
Внимание
Сервис устанавливается на сервер мониторинга.
Проверить последнюю версию Grafana можно в документации
sudo apt-get install -y adduser libfontconfig1 musl
wget https://dl.grafana.com/grafana-enterprise/release/<VERSION>/grafana-enterprise_<VERSION>_<OS>_<ARCH>.deb
sudo dpkg -i grafana-enterprise_<VERSION>_<OS>_<ARCH>.deb
sudo systemctl enable --now grafana-server
Доступ#
Интерфейс доступен по адресу:
http://<IP_ADDRESS>:3000
Стандартные учетные данные:
admin / admin: после первого входа система предложит изменить пароль - задайте надёжный.
Установка Loki#
Внимание
Сервис устанавливается на сервер мониторинга.
Загрузка и установка#
Проверить последний релиз можно в репозитории.
wget https://github.com/grafana/loki/releases/download/v<VERSION>/loki_<VERSION>_<ARCH>.deb
sudo apt install loki_<VERSION>_<ARCH>.deb
В сервисе loki.service приведите стартовый параметр к следующему виду:
ExecStart=/usr/bin/loki -config.file /etc/loki/config.yml -config.expand-env=true
Конфигурация#
Создайте файл конфигурации /etc/loki/config.yml.
Пример рекомендуемой конфигурации
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
log_level: debug
grpc_server_max_concurrent_streams: 1000
grpc_server_max_recv_msg_size: 209715200
grpc_server_max_send_msg_size: 209715200
common:
instance_addr: 127.0.0.1
path_prefix: /tmp/loki
storage:
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
limits_config:
metric_aggregation_enabled: true
max_entries_limit_per_query: 1000000
query_timeout: 10m
max_global_streams_per_user: 10000
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h
pattern_ingester:
enabled: true
metric_aggregation:
loki_address: localhost:3100
ruler:
alertmanager_url: http://localhost:9093
frontend:
encoding: protobuf
analytics:
reporting_enabled: false
Запуск и автозагрузка#
sudo systemctl daemon-reload
sudo systemctl start loki
sudo systemctl enable loki.service
sudo systemctl status loki
Установка Promtail#
Внимание
Сервис устанавливается как на сервер приложений, так и на сервер СУБД.
Загрузка и установка#
Проверить последний релиз можно в репозитории.
https://github.com/grafana/loki/releases/download/v3.5.7/promtail_3.5.7_amd64.deb
wget "https://github.com/grafana/loki/releases/download/v<VERSION>/promtail_<VERSION>_<ARCH>.zip"
sudo apt install promtail_<VERSION>_<ARCH>.deb
Запуск и проверка#
sudo systemctl start promtail
sudo systemctl status promtail
Конфигурация Promtail#
Отредактируйте основной файл конфигурации /etc/promtail/config.yml:
Пример рекомендуемой конфигурации для сервера приложений
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://<IP Адрес сервера метрик>:3100/loki/api/v1/push
scrape_configs:
- job_name: haproxy
static_configs:
- targets:
- localhost
labels:
job: "haproxy"
host: "<IP Адрес сервера приложений>"
service: "HAProxy"
__path__: /var/log/haproxy.*
pipeline_stages:
- regex:
expression: '^(?P<timestamp>\S+\s+\d+\s+\S+)\s+(?P<hostname>\S+)\s+haproxy\[(?P<pid>\d+)\]:\s+(?P<client_ip>\S+):(?P<client_port>\d+)\s+\[(?P<accept_time>[^\]]+)\]\s+(?P<frontend>\S+)\s+(?P<backend>\S+)\/(?P<server>\S+)\s+(?P<tq>\d+)\/(?P<tw>\d+)\/(?P<tc>\d+)\/(?P<tr>\d+)\/(?P<tt>\d+)\s+(?P<status_code>\d+)\s+(?P<bytes_read>\d+)\s+(?P<captured_request_headers>\S+)\s+(?P<captured_response_headers>\S+)\s+(?P<termination_state>\S+)\s+(?P<actconn>\d+)\/(?P<feconn>\d+)\/(?P<beconn>\d+)\/(?P<srvconn>\d+)\/(?P<retries>\d+)\s+(?P<srv_queue>\d+)\/(?P<backend_queue>\d+)\s+\{(?P<request_headers>[^}]+)\}\s+\{(?P<response_headers>[^}]+)\}\s+"(?P<http_request>[^"]+)"'
- labels:
client_ip:
frontend:
backend:
server:
status_code:
termination_state:
- job_name: global3
static_configs:
- targets:
- localhost
labels:
job: "Global"
host: "<IP Адрес сервера приложений>"
service: "Global_3"
__path__: /opt/global/globalserver/logs/*
pipeline_stages:
- multiline:
firstline: '\['
- regex:
expression:
'^(?s)\[(?P<time>\d{2}-\d{2}-\d{4} \d{2}:\d{2}:\d{2}\.\d{3})\] \[(?P<level>[A-Z ]*)\] \[(?P<thread>.*)\] \[(?P<logger>[^ ]*)\] \[(?P<user>[^ ]*)\] - (?P<msg>.*)$'
- labels:
level:
thread:
logger:
user:
- timestamp:
source: time
format: 01-01-2025 13:30:30.000
location: Europe/Moscow
- labeldrop:
- filename
- time
- output:
source: msg
- job_name: globalscheduler
static_configs:
- targets:
- localhost
labels:
job: "globalscheduler"
host: "<IP Адрес сервера приложений>"
service: "Global_Scheduler"
__path__: /opt/global/globalserver/logs/scheduler/jobscheduler.*
pipeline_stages:
- multiline:
firstline: '\['
- regex:
expression:
'^(?s)\[(?P<time>\d{2}-\d{2}-\d{4} \d{2}:\d{2}:\d{2}\.\d{3})\] \[(?P<level>[A-Z ]*)\] \[(?P<thread>.*)\] \[(?P<logger>[^ ]*)\] - (?P<msg>.*)$'
- labels:
level:
thread:
logger:
- timestamp:
source: time
format: 01-01-2025 13:30:30.000
location: Europe/Moscow
- labeldrop:
- filename
- time
- output:
source: msg
Выдайте права на чтение логов:
sudo setfacl -R -m u:promtail:rX /var/log/
sudo chown promtail /var/log/haproxy.log
Пример рекомендуемой конфигурации для сервера СУБД
:server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://<IP Адрес сервера метрик>:3100/loki/api/v1/push
scrape_configs:
- job_name: postgresql
static_configs:
- targets:
- localhost
labels:
job: postgresql
service: "PostgreSQL"
__path__: /var/log/postgresql/postgresql-17-main.*
pipeline_stages:
- regex:
expression: '^(?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3}) \[\d+\] (?P<user_database>\w+@\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}|\w+@local)?:\w+ \[\d+\] (?P<level>\w+): (?P<message>.*)$'
- labels:
level:
user_database:
timestamp:
- job_name: pgbouncer
static_configs:
- targets:
- localhost
labels:
job: pgbouncer
service: "PgBouncer"
__path__: /var/log/postgresql/pgbouncer.*
pipeline_stages:
- regex:
expression: '^(?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3}) \[\d+\] (?P<user_database>\w+@\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}|\w+@local)?:\w+ \[\d+\] (?P<level>\w+): (?P<message>.*)$'
- labels:
level:
user_database:
timestamp:
Выдайте права на чтение логов:
sudo setfacl -R -m u:promtail:rX /var/log/
sudo usermod -a -G systemd-journal promtail
Раскомментируйте и настройте следующие строки в /etc/postgresql/*/main/postgresql.conf:
log_destination = 'stderr'
log_rotation_age = 3d
log_min_messages = warning
log_min_error_statement = error
Установка OpenTelemetry Collector#
Подробности: opentelemetry.io/docs/collector
Настройка Otelcol сервиса#
Внимание
Сервис устанавливается на сервер приложений.
Проверить последний релиз можно в репозитории.
sudo apt-get update
sudo apt-get install -y wget
wget https://github.com/open-telemetry/opentelemetry-collector-releases/releases/download/v<VERSION>/otelcol_<VERSION>_<OS>_<ARCH>.deb
sudo apt install otelcol_<VERSION>_<OS>_<ARCH>.deb
Отредактируйте конфигурационный файл: /etc/otelcol-contrib/config.yaml
Пример рекомендуемой конфигурации
extensions:
health_check:
pprof:
endpoint: 0.0.0.0:1777
zpages:
endpoint: 0.0.0.0:55679
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
# Collect own metrics
prometheus:
config:
scrape_configs:
- job_name: 'otel-collector'
scrape_interval: 10s
static_configs:
- targets: [ '0.0.0.0:8888' ]
jaeger:
protocols:
grpc:
endpoint: 0.0.0.0:14250
thrift_binary:
endpoint: 0.0.0.0:6832
thrift_compact:
endpoint: 0.0.0.0:6831
thrift_http:
endpoint: 0.0.0.0:14268
zipkin:
endpoint: 0.0.0.0:9411
processors:
batch:
exporters:
debug:
verbosity: detailed
prometheusremotewrite:
endpoint: http://<IP Адрес сервера метрик>:9090/api/v1/write
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 60s
max_elapsed_time: 120s
service:
pipelines:
traces:
receivers: [ otlp, jaeger, zipkin ]
processors: [ batch ]
exporters: [ debug ]
metrics:
receivers: [ otlp, prometheus ]
processors: [ batch ]
exporters: [ debug, prometheusremotewrite ]
logs:
receivers: [ otlp ]
processors: [ batch ]
exporters: [ debug ]
extensions: [ health_check, pprof, zpages ]
Запустите сервис:
sudo systemctl stop otelcol-contrib
sudo systemctl start otelcol-contrib
sudo systemctl status otelcol-contrib
Настройка сервера приложений#
В папку с дистрибутивом проекта global/globalserver/application/config/ добавить файл: otel-sdk.config.yaml
Пример рекомендуемой конфигурации
file_format: "0.1"
disabled: false
resource:
attributes:
service.name: Global
#service.name: ${env:OTEL_SERVICE_NAME}
exporters:
otlp: &otlp-exporter
timeout: 10000
# https://opentelemetry.io/docs/specs/otel/protocol/exporter/#specify-protocol
protocol: grpc
endpoint: http://localhost:4318
logger_provider:
processors:
- batch:
exporter:
otlp: *otlp-exporter
meter_provider:
readers:
- periodic:
interval: 5000
timeout: 30000
exporter:
otlp:
timeout: 10000
protocol: grpc
endpoint: http://localhost:4317
tracer_provider:
processors:
- batch:
exporter:
otlp:
timeout: 10000
protocol: http/protobuf
endpoint: http://localhost:4318
И файл otel-globalserver.config.yaml с содержимым
instrumentation:
common:
default-enabled: true
runtime-telemetry:
enabled: true
emit-experimental-telemetry:
enabled: true
logback-appender:
enabled: true
Настройка HAProxy#
Подробнее о настройке выдачи метрик HAProxy в Prometheus в Руководстве по настройке HAProxy.
Установка Node Exporter#
Внимание
Сервис устанавливается на сервер приложений и, при необходимости, на сервер СУБД
Проверить последний релиз можно в репозитории
wget https://github.com/prometheus/node_exporter/releases/download/v<VERSION>/node_exporter-<VERSION>.<OS>-<ARCH>.tar.gz
tar xvfz node_exporter-*.tar.gz
sudo mv node_exporter-<VERSION>.<OS>-<ARCH>/node_exporter /usr/local/bin/
sudo useradd --no-create-home --shell /bin/false node_exporter
sudo chown node_exporter:node_exporter /usr/local/bin/node_exporter
Создайте сервис: /etc/systemd/system/node_exporter.service
[Unit]
Description=Node Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=/usr/local/bin/node_exporter --web.listen-address=:9100 --collector.systemd --collector.processes --collector.nfs
[Install]
WantedBy=multi-user.target
Запустите сервис:
sudo systemctl daemon-reload
sudo systemctl enable node_exporter
sudo systemctl start node_exporter
sudo systemctl status node_exporter
Установка Postgres Exporter#
Внимание
Сервис устанавливается на сервер СУБД.
Проверить последний релиз можно в репозитории.
wget https://github.com/prometheus-community/postgres_exporter/releases/download/v<VERSION>/postgres_exporter-<VERSION>.<OS>-<ARCH>.tar.gz
tar -xf postgres_exporter-*.tar.gz
sudo cp postgres_exporter /usr/local/bin/
sudo chown -R postgres:postgres /usr/local/bin/postgres_exporter
Создайте сервис: /etc/systemd/system/postgres_exporter.service.
[Unit]
Description=Prometheus PostgreSQL Exporter
After=network.target
[Service]
Type=simple
Restart=always
User=postgres
Group=postgres
Environment=DATA_SOURCE_NAME="user=postgres host=/var/run/postgresql/ sslmode=disable"
ExecStart=/usr/local/bin/postgres_exporter
[Install]
WantedBy=multi-user.target
Запустите сервис:
sudo systemctl daemon-reload
sudo systemctl start postgres_exporter.service
sudo systemctl enable postgres_exporter.service
Установка pgSCV#
Внимание
Сервис устанавливается на сервер СУБД. Используется для снятия метрик с Postgres, Pgbouncer.
Установка сервиса:
Проверить последний релиз можно в репозитории.
curl -s -L https://github.com/cherts/pgscv/releases/download/v<VERSION>/pgscv_<VERSION>_linux_<ARCH>.tar.gz -o - | tar xzf - -C /tmp && \
mv /tmp/pgscv.yaml /etc && \
mv /tmp/pgscv.service /etc/systemd/system && \
mv /tmp/pgscv.default /etc/default/pgscv && \
mv /tmp/pgscv /usr/sbin && \
chown postgres:postgres /etc/pgscv.yaml && \
chmod 640 /etc/pgscv.yaml && \
systemctl daemon-reload && \
systemctl enable pgscv --now
Приведите сервис /etc/systemd/system/pgscv.service к следующему виду:
[Unit]
Description=pgSCV - PostgreSQL ecosystem metrics collector
Documentation=https://github.com/cherts/pgscv/wiki
Requires=network-online.target
After=postgresql.service
Wants=postgresql.service
[Service]
Type=simple
User=postgres
Group=postgres
EnvironmentFile=-/etc/default/pgscv
# Start the agent process
ExecStart=/usr/sbin/pgscv $ARGS
# Kill all processes in the cgroup
KillMode=control-group
# Wait reasonable amount of time for agent up/down
TimeoutSec=5
# Restart agent if it crashes
Restart=on-failure
RestartSec=10
# if agent leaks during long period of time, let him to be the first person for eviction
OOMScoreAdjust=1000
[Install]
WantedBy=multi-user.target
Создайте нового пользователя в postgres:
CREATE ROLE pgscv WITH LOGIN PASSWORD 'SUPERSECRETPASSWORD';
GRANT pg_read_server_files, pg_monitor TO pgscv;
GRANT EXECUTE on FUNCTION pg_current_logfile() TO pgscv;
Выполните команду, которая выведет хеш пароля для пользователя pgbouncer, и сохраните его. Он понадобится при настройке аутентификации pgbouncer.
SELECT passwd FROM pg_shadow WHERE usename = 'pgscv';
Отредактируйте файл
/etc/pgbouncer/pgbouncer.ini. Добавьте строку:stats_users = pgscv.Для работы аутентификации с вышеописанными настройками, в userlist.txt требуется установить следующие значения:
"pgscv" "<scram-sha-256 хеш пароля для пользователя pgbouncer>"
Убедитесь, что в файле pg_hba.conf указан метод аутентификации scram-sha-256:
host all all all scram-sha-256
Перезапустите PgBouncer:
sudo systemctl restart pgbouncer
Удалите дефолтный
pgscv.yamlи создайте новый:
cat << EOF > /etc/pgscv.yaml
listen_address: 0.0.0.0:9890
services:
"postgres:5432":
service_type: "postgres"
conninfo: "postgres://pgscv:SUPERSECRETPASSWORD@127.0.0.1:<db_port>/<global_db_name>"
"pgbouncer:6432":
service_type: "pgbouncer"
conninfo: "postgres://pgscv:SUPERSECRETPASSWORD@127.0.0.1:<pgbouncer_port>/pgbouncer"
EOF
Выдайте необходимые права:
sudo chown postgres:postgres /etc/pgscv.yaml
sudo chmod 640 /etc/pgscv.yaml
Запустите сервис:
sudo systemctl daemon-reload
sudo systemctl enable pgscv.service
sudo systemctl start pgscv.service
sudo systemctl status pgscv.service
Проверьте работу сервиса. Значения должны быть больше нуля.
curl -s http://127.0.0.1:9890/metrics | grep -c ^postgres
curl -s http://127.0.0.1:9890/metrics | grep -c ^pgbouncer
curl -s http://127.0.0.1:9890/metrics | grep -c ^node
curl -s http://127.0.0.1:9890/metrics | grep -c ^go
Настройка Global3 и GlobalScheduler#
Необходимо включить вывод логов в указанную в конфигурационном файле Promtail директорию.
По умолчанию для Global3: /opt/global/globalserver/logs/.
Подробнее в руководстве по Global3.
По умолчанию для GlobalScheduler: /opt/global/globalserver/logs/scheduler/.
Подробнее в руководстве по GlobalScheduler.
Запуск скрипта снятия дополнительных метрик#
Внимание
Сервис устанавливается на сервер приложений.
Необходимо загрузить и распаковать архив:
wget https://repo.global-system.ru/artifactory/general/ru/bitec/monitoring-tool-standalone/telemetry_agent_standalone.zip
unzip telemetry_agent_standalone.zip /path/to/directory
Структура#
telemetry_agent_standalone/
bin/
bootstrap.sh # создает .venv и устанавливает зависимости
lib/
gs_agents.py
opentel.py
GsTelemetryAgent.py
run.sh # запускает GsTelemetryAgent.py
install_service.sh # создаёт unit, включает и запускает сервис
uninstall_service.sh # удаляет unit, выключает сервис
requirements.txt
README.md
Быстрый старт#
cd telemetry_agent_standalone
sudo find -type f -name '*.sh' -exec chmod a+x {} \;
sudo ./run.sh
Установка как сервис#
При необходимости, перенести проект в удобное место. Например /opt. После этого запустите скрипт на выполнение:
sudo ./install_service.sh
Юнит будет создан по пути /etc/systemd/system/gs-telemetry.service.
Удаление сервиса#
При необходимости удалить сервис и venv, запустите:
sudo ./uninstall_service.sh
13. Добавление дашбордов в Grafana#
После настройки сбора всех метрик, необходимо перейти на страницу grafana для добавления визуальных дашбордов (досок) для мониторинга состояния системы.
Подключение источников данных#
В Grafana откройте меню
Connections -> Data sources -> Add new data source.Выберите Prometheus.
В поле Prometheus server URL укажите адрес сервера мониторинга (http://<IP_ADDRESS>:9090).
Нажмите Save & test.
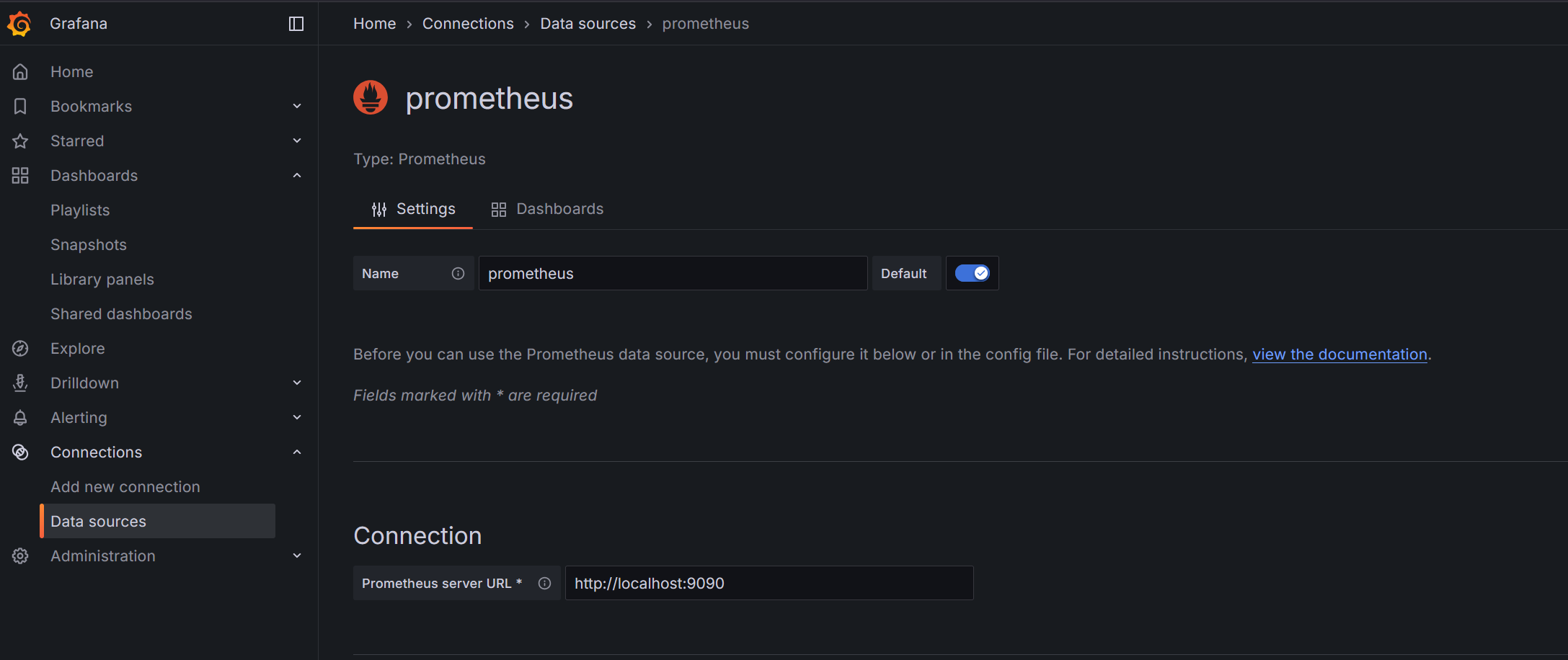
Таким же образом добавьте Loki как источник данных, указав адрес сервера мониторинга (http://<IP_ADDRESS>:3100).
Примечание
Если вы устанавливали Grafana, Prometheus, Loki на один сервер, в url источника данных можно прописывать localhost.
Импорт готовых дашбордов#
Скачайте все необходимые дашборды по ссылке.
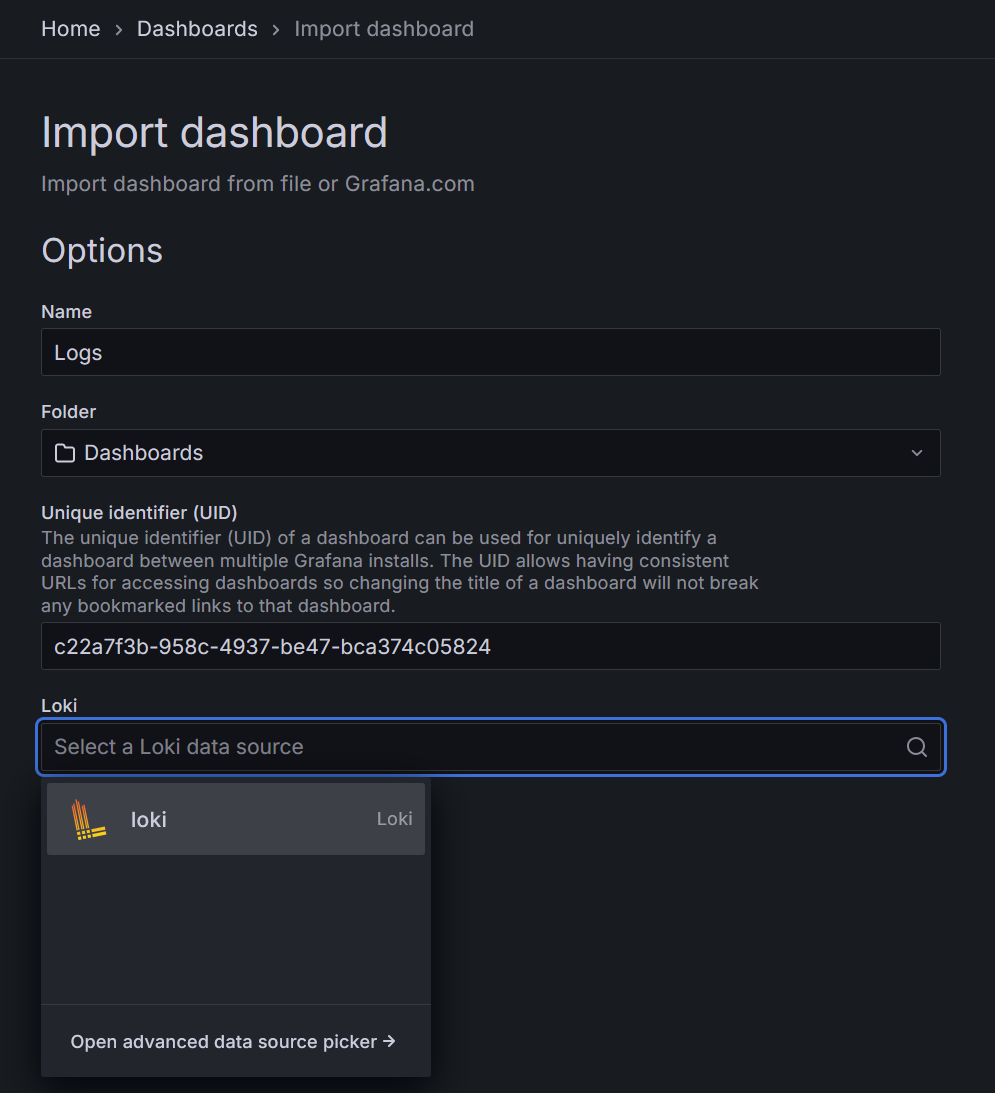
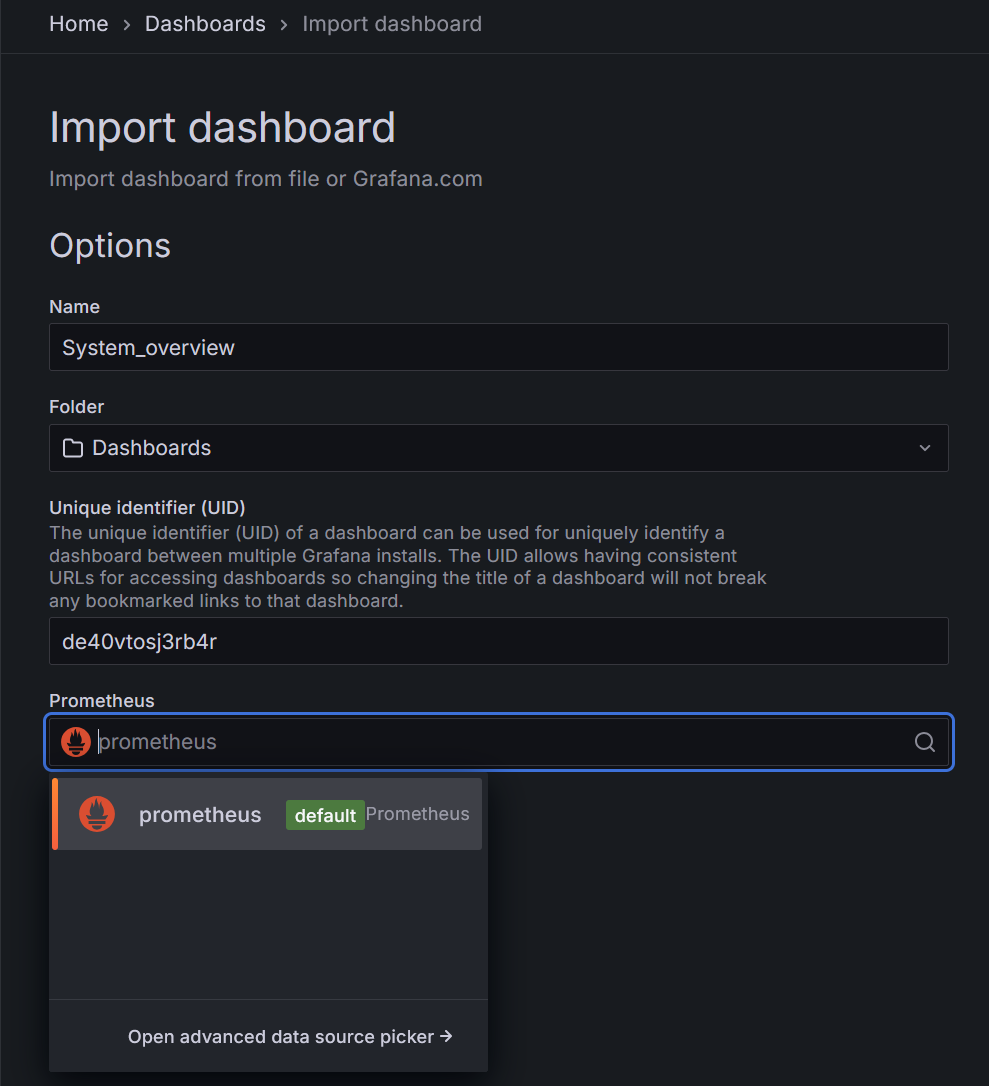
Перейдите на вкладку Dashboards. Справа сверху кнопка New - Import. Загрузите по одному дашборды.
Если дашборд относится к отображению логов, в источнике данных выберете Loki:
Иначе - Prometheus:
13.3 Обзор основных метрик#
Global Logs
Дашборд для оперативного анализа логов из Loki по ключевым сервисам платформы Global (Global Server, Global Scheduler, HAProxy, PostgreSQL, PgBouncer).
Global Server Logs - Поток логов сервиса Global Server из Loki.
Global Scheduler Logs - Поток логов сервиса Global Scheduler из Loki.
HAProxy - Поток логов сервиса HAProxy из Loki.
PgBouncer - Поток логов сервиса PgBouncer из Loki.
PostgreSQL - Поток логов сервиса PostgreSQL из Loki.
HAProxy
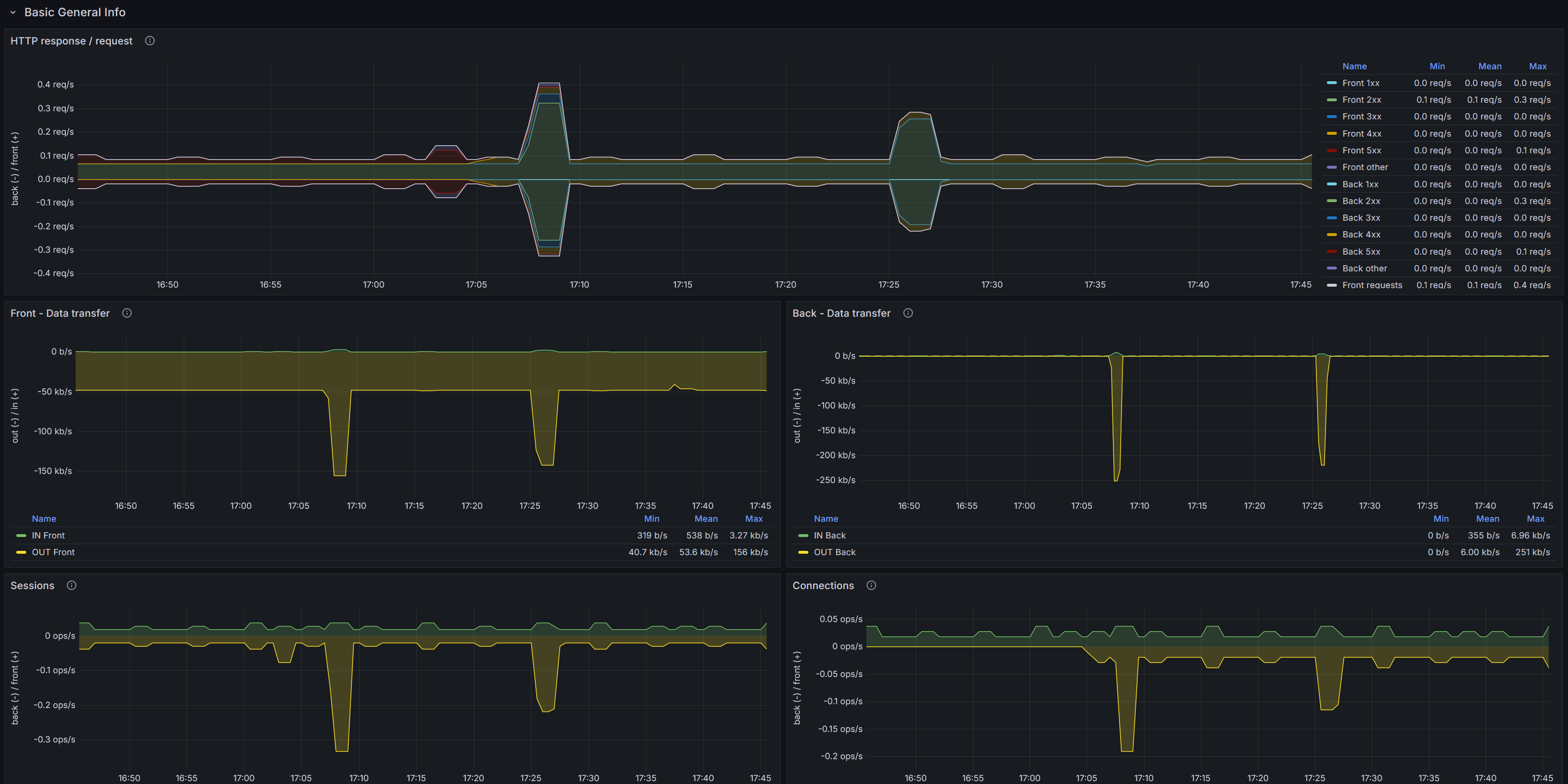
Мониторинг HAProxy на основе метрик Prometheus.
HTTP response / request - Скорость запросов и ответов через HAProxy на фронтендах и бэкендах.
Front - Data transfer - Трафик через фронтенды (бит/с): IN - входящий трафик, OUT - исходящий.
Back - Data transfer - Трафик через бэкенды (бит/с): IN - входящий трафик, OUT - исходящий.
Sessions - Скорость установления сессий (ops) на фронтендах и бэкендах.
Connections - Скорость установления соединений: фронтенды (connections_total) и попытки соединений к бэкендам ( connection_attempts_total).
Status UP - Количество фронтендов и бэкендов в состоянии UP (значение state == 1).
Uptime - Аптайм процесса HAProxy (в секундах): разница между текущим временем и временем старта процесса.
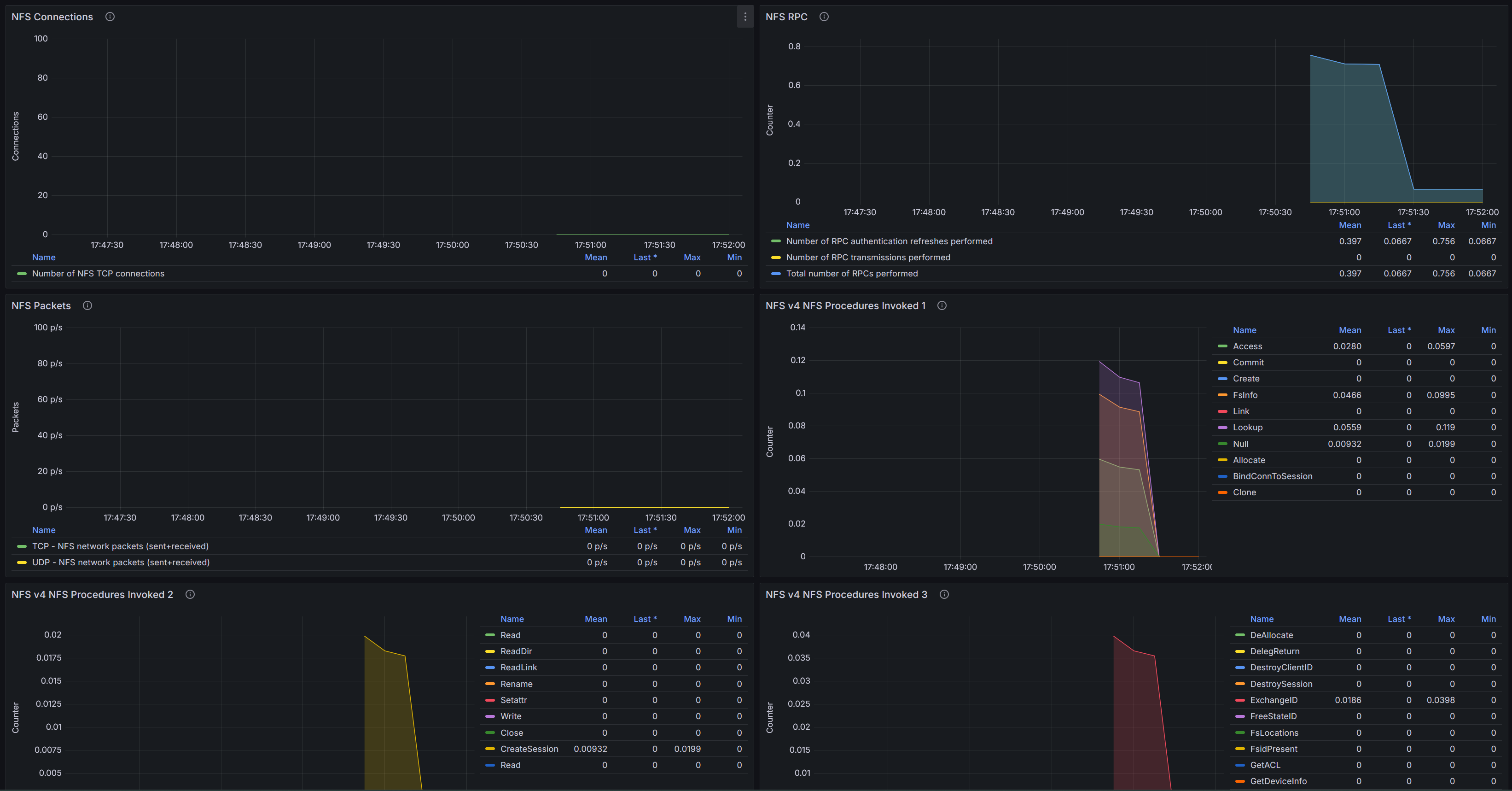
NFS
Дашборд мониторинга NFS (клиент/сервер) по метрикам node_exporter/Prometheus.
NFS Connections - Скорость установления TCP‑соединений NFS (conn/s).
NFS RPC - Активность RPC NFS (ops/s): всего RPC, ретрансляции (retransmissions) и обновления аутентификации.
NFS Packets - Скорость сетевых пакетов NFS (pps) по протоколам TCP и UDP - суммарно отправленные и полученные.
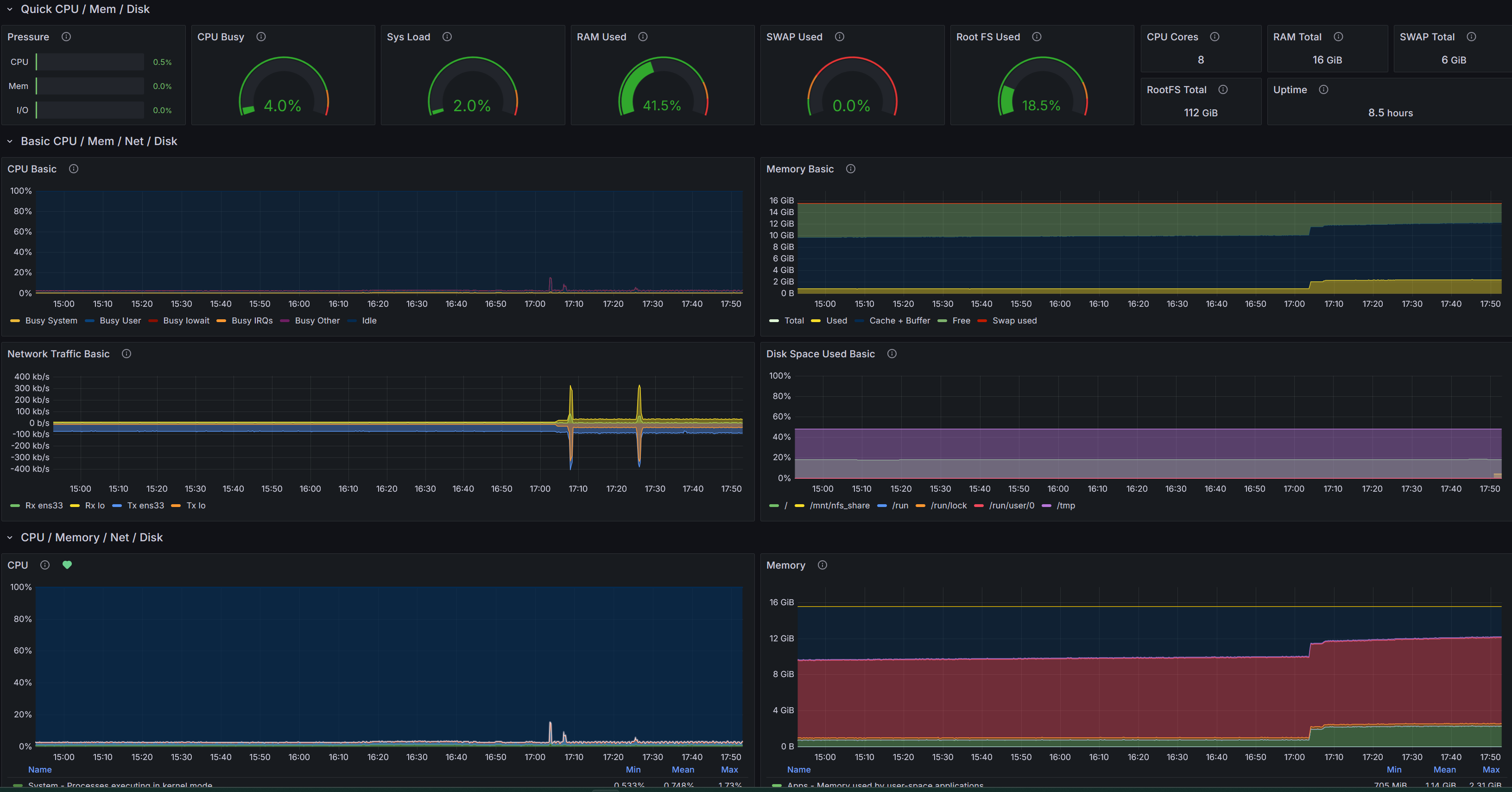
Node Exporter Full
Дашборд по node_exporter: CPU (включая PSI/Pressure), нагрузка (load), память и SWAP, файловые системы, сеть (Rx/Tx, ошибки), диски (I/O, latency), процессы и системные счётчики.
Pressure - PSI (Pressure Stall Information): доля времени, когда задачи простаивают из‑за нехватки ресурса - CPU, Memory, I/O или IRQ.
CPU Busy - CPU: время, затраченное ядрами в различных режимах (user, system, iowait, irq, softirq, steal, idle), нормировано на количество ядер.
RAM Used - Память: объём всего/занятого/свободного, кэш/буферы, SReclaimable и др.
SWAP Used - Память: разбивка RAM (занято, кэш/буферы, свободно) и использование SWAP.
Root FS Used - Использование пространства файловых систем (проценты/байты) по каждому mountpoint.
RAM Total - Память: объём всего/занятого/свободного, кэш/буферы, SReclaimable и др.
SWAP Total - Память: разбивка RAM (занято, кэш/буферы, свободно) и использование SWAP.
RootFS Total - Использование пространства файловых систем (проценты/байты) по каждому mountpoint.
Uptime - Аптайм узла в секундах: разница между текущим временем и временем загрузки системы.
CPU Basic - CPU: время, затраченное ядрами в различных режимах (user, system, iowait, irq, softirq, steal, idle), нормировано на количество ядер.
Memory Basic - Память: разбивка RAM (занято, кэш/буферы, свободно) и использование SWAP.
Network Traffic Basic - Сеть: трафик по интерфейсам (Rx/Tx в бит/с), возможен вывод ошибок/дропов; Tx часто показывается отрицательным для симметрии.
Disk Space Used Basic - Использование пространства файловых систем (проценты/байты) по каждому mountpoint.
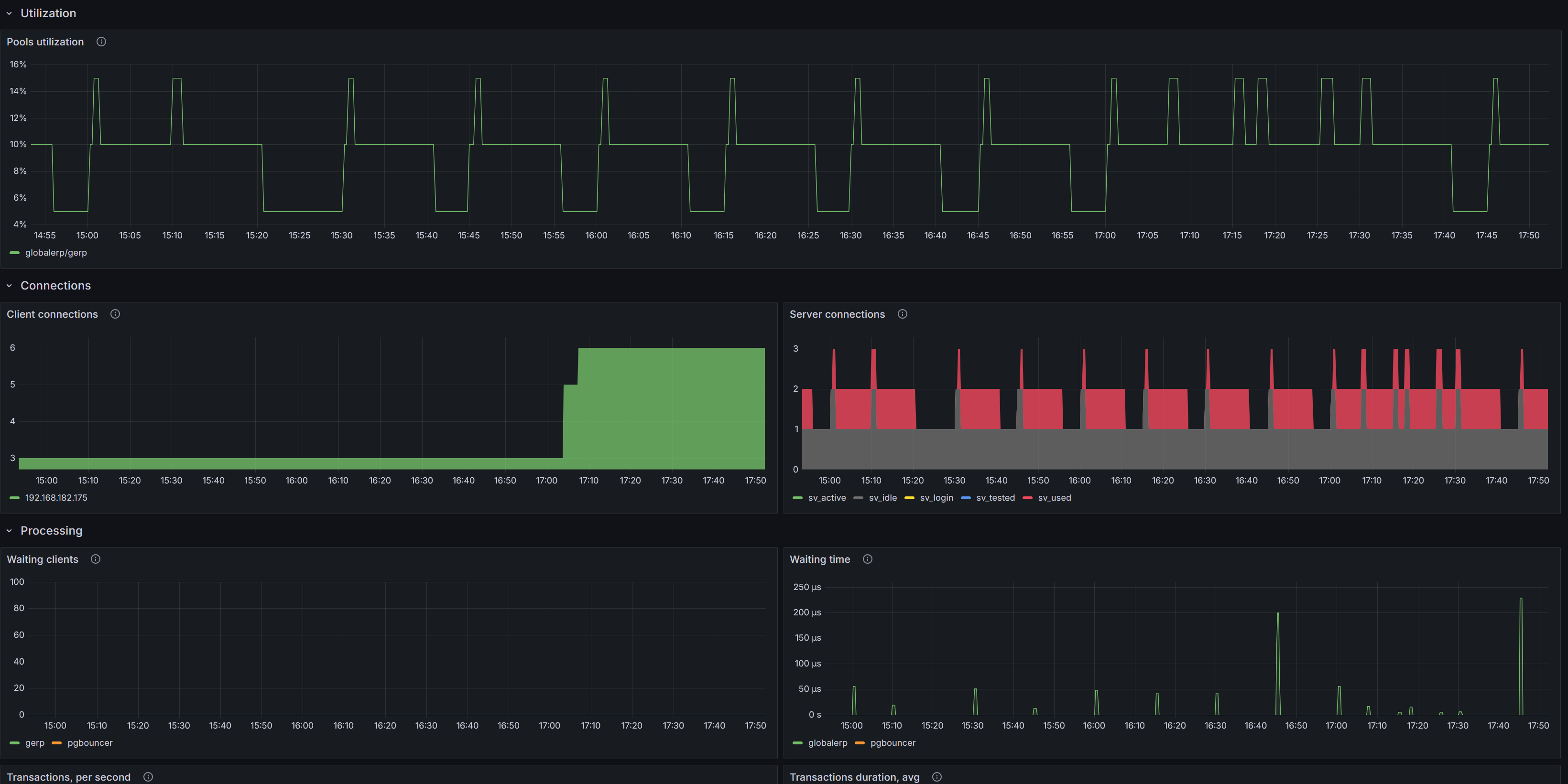
pgSCV: Pgbouncer
Дашборд pgSCV для PgBouncer: состояние сервиса, загрузка пулов, соединения клиентов/серверов, транзакции и запросы, сетевой трафик и параметры конфигурации.
Status - Состояние PgBouncer (UP/DOWN) по метрике pgbouncer_up{service_id=»$pgbouncer»}.
Clients - Число активных клиентских соединений к PgBouncer (без базы pgbouncer): sum( pgbouncer_client_connections_in_flight).
Server connections - Число активных серверных соединений от PgBouncer к PostgreSQL.
Version - Текущая версия PgBouncer из метрики pgbouncer_version.
Pools utilization - Процент использования пулов (database/user).
Client connections - Топ-5 адресов по числу клиентских соединений (max_over_time за 1м) - кто создаёт наибольшую нагрузку на PgBouncer.
Server connections - Число активных серверных соединений от PgBouncer к PostgreSQL.
Waiting clients - Ожидающие клиенты (cl_waiting): топ-5 пользователей по числу ожидающих серверного соединения.
Waiting time - Время ожидания (сек/с) - rate(pgbouncer_spent_seconds_total{type=»waiting»}) по базам.
Transactions, per second - Транзакции в сек: rate(pgbouncer_transactions_total) по базам.
Network traffic - Сетевой трафик PgBouncer (бит/с): rate(pgbouncer_bytes_total) по типам (received/sent).
pgSCV: PostgreSQL
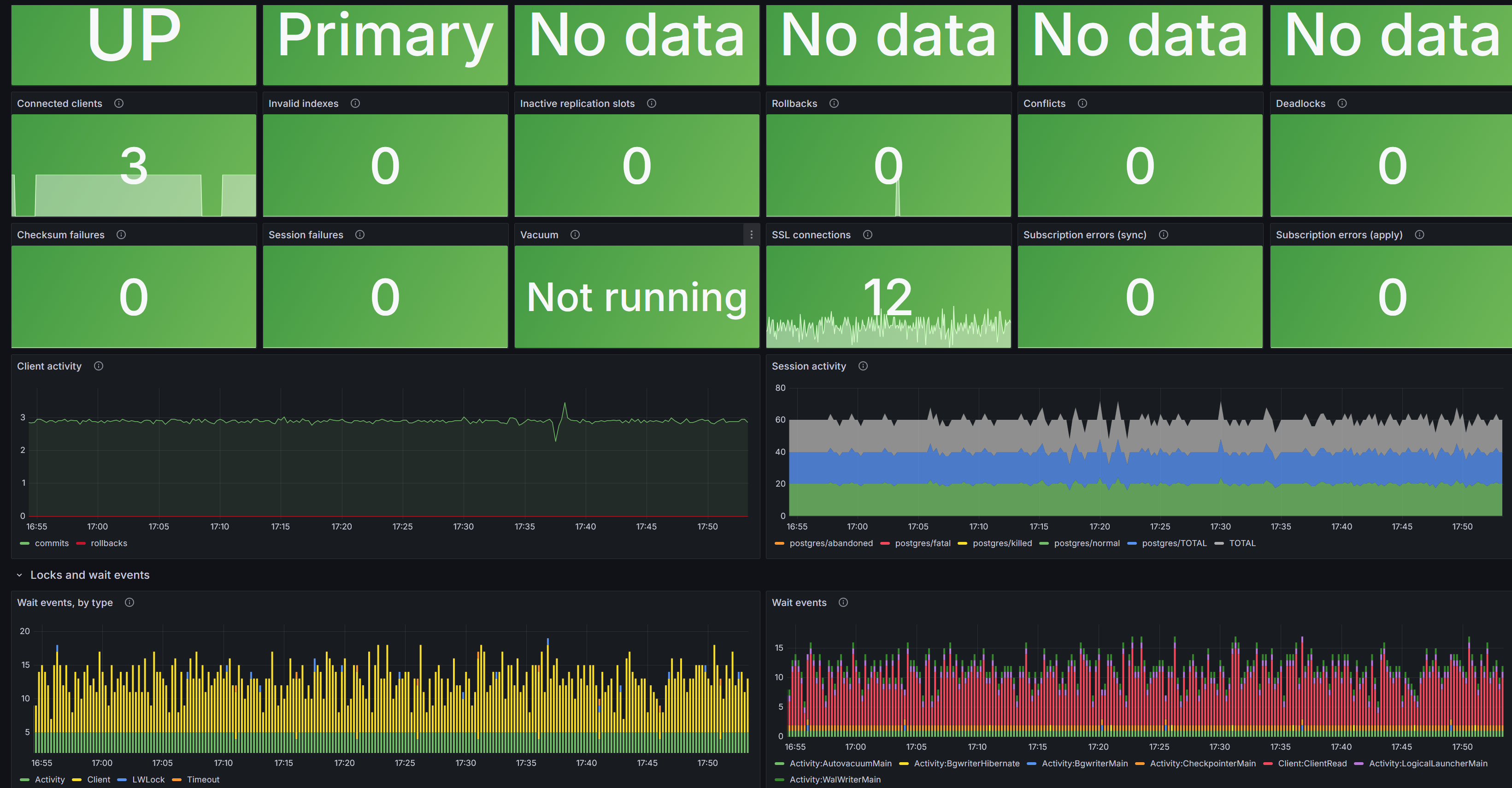
Дашборд PostgreSQL по метрикам pgSCV: состояние сервиса и роль, активность клиентов, длительности и ошибки, сессии, блокировки и события ожидания, репликация и другое.
Service status - Состояние сервиса PostgreSQL.
Role - Текущая роль узла: Primary или Replica.
Errors - Частота сообщений в логах уровня выше LOG (WARNING/ERROR/FATAL/PANIC) в минуту.
Response time, avg - Среднее время ответа (сек/запрос).
Longest activity - Максимальная текущая длительность активности (сек): учитывает клиентов и фоновые сервисы.
Connected clients - Общее число клиентских соединений по всем базам.
Invalid indexes - Число невалидных индексов в кластере.
Inactive replication slots - Количество неактивных слотов репликации.
Rollbacks - Число откатов транзакций в минуту.
Conflicts - Конфликты в минуту.
Deadlocks - Дедлоки в минуту.
Checksum failures - Ошибки контрольных сумм в минуту.
Session failures - Сессии, завершённые по причинам abandoned/fatal/killed.
SSL connections - Число SSL-соединений к базам данных.
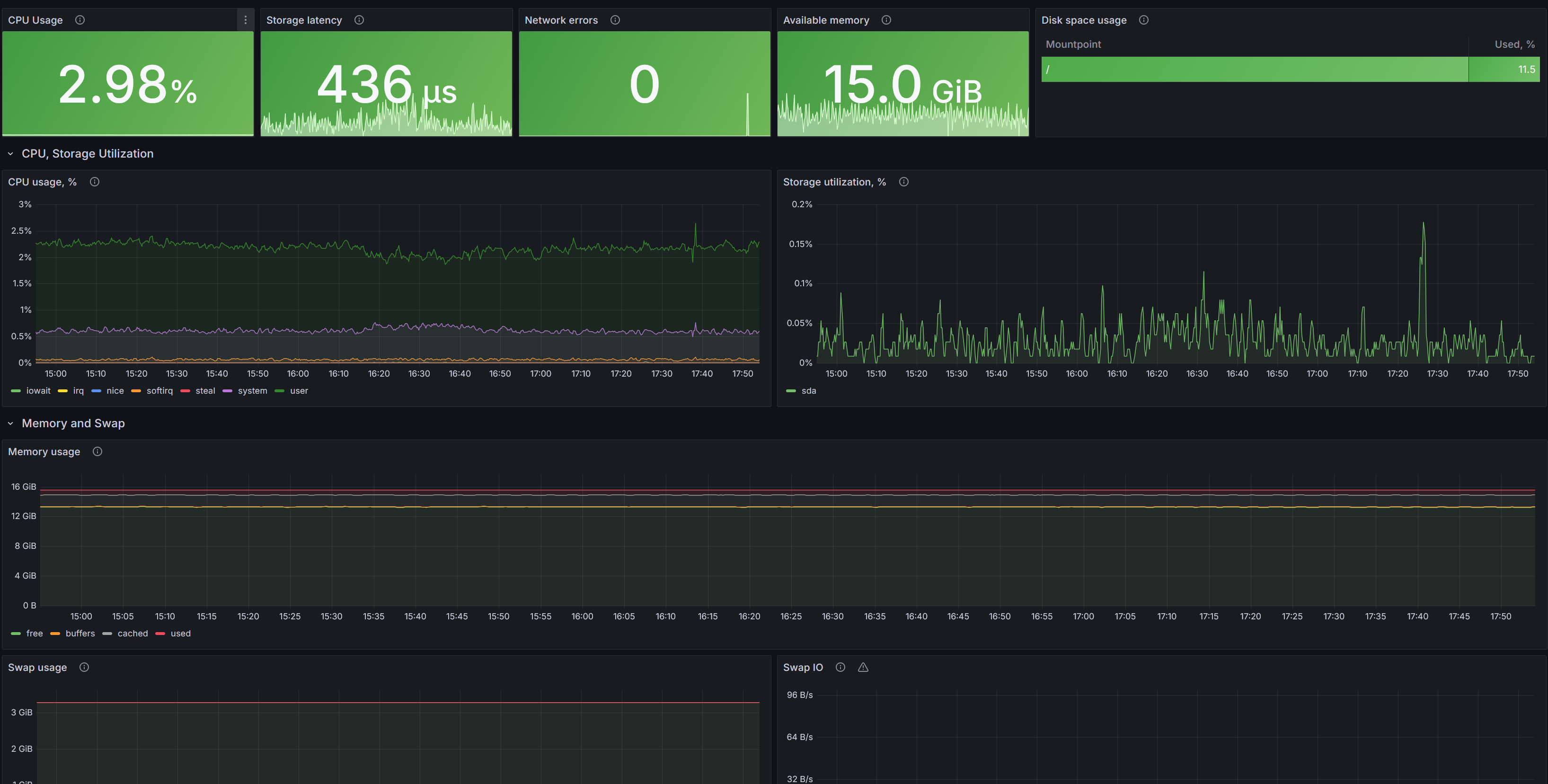
pgSCV: System
Системный дашборд для метрик pgSCV: CPU и утилизация, латентность/пропускная способность хранилища, память и SWAP, файловые системы (использование по точкам монтирования), а также сеть (байты/пакеты/ошибки).
CPU Usage - Текущая загрузка CPU, %.
Storage latency - Текущая средняя латентность операций ввода/вывода (сек/операцию) по всем устройствам.
Network errors - Сумма сетевых ошибок за минуту по всем интерфейсам (errs/fifo/frame/drop).
Available memory - Доступная память (MemFree + Cached + Buffers).
Disk space usage - Максимальное использование дискового пространства по файловым системам, % (таблица).
CPU usage, % - Загрузка CPU по режимам (user/system/iowait/irq/); нормировано на количество ядер.
Storage utilization, % - Утилизация устройств хранения, %: доля времени, когда устройство занято I/O.
Memory usage - Использование памяти: free, buffers, cached, used - средние за минуту.
Swap usage - Использование SWAP: свободно/занято - средние за минуту.
Swap IO - Swap I/O, байт/с: скорость подкачки (ввод/вывод) на уровне ОС.
Storage latency, ms - Латентность устройств хранения в динамике (сек/операцию) по устройствам.
Read, bytes per second - Скорость чтения, байт/с, по устройствам.
Write, bytes per second - Скорость записи, байт/с, по устройствам.
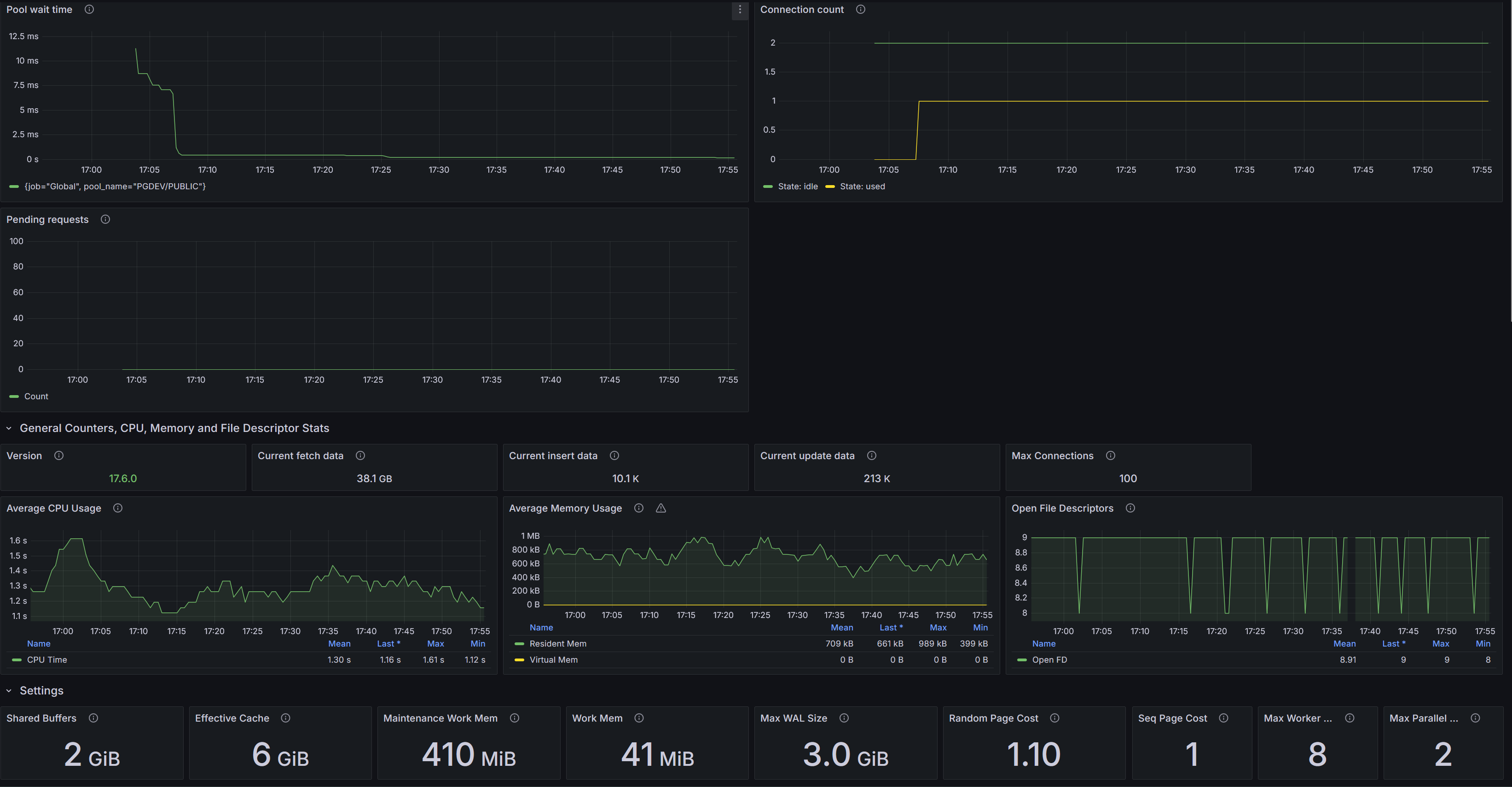
PostgreSQL Database
Дашборд PostgreSQL на основе метрик postgres_exporter (Prometheus).
Pool wait time - Среднее время ожидания получения соединения из пула (сек) по выбранным пулам.
Connection count - Количество соединений клиентов по состояниям (active/idle/); агрегировано по пулу.
Pending requests - Текущее число ожидающих запросов на получение соединения из пула.
Version - Версия PostgreSQL из метрики pg_static (short_version).
Current fetch data - Суммарное чтение строк (tup_fetched) по выбранным базам данных.
Current insert data - Суммарное число вставленных строк (tup_inserted) по выбранным базам.
Current update data - Суммарное число обновлённых строк (tup_updated) по выбранным базам.
Max Connections - Текущее значение параметра max_connections (pg_settings).
Average CPU Usage - Среднее потребление CPU процессом postgres за интервал (сек/с).
Average Memory Usage - Средние значения виртуальной и резидентной памяти процесса postgres.
Shared Buffers - Размер shared_buffers - объём буферного кеша сервера.
Effective Cache - Значение effective_cache_size - ориентир доступного файлового кеша ОС.
Maintenance Work Mem - maintenance_work_mem - память для VACUUM/CREATE INDEX и др.
Work Mem - work_mem - память на сортировку/хеш на один узел выполнения и одну сессию.
Max WAL Size - max_wal_size - целевой верхний предел объёма WAL.
Random Page Cost - random_page_cost - относительная стоимость случайного чтения блока.
Seq Page Cost - seq_page_cost - относительная стоимость последовательного чтения блока.
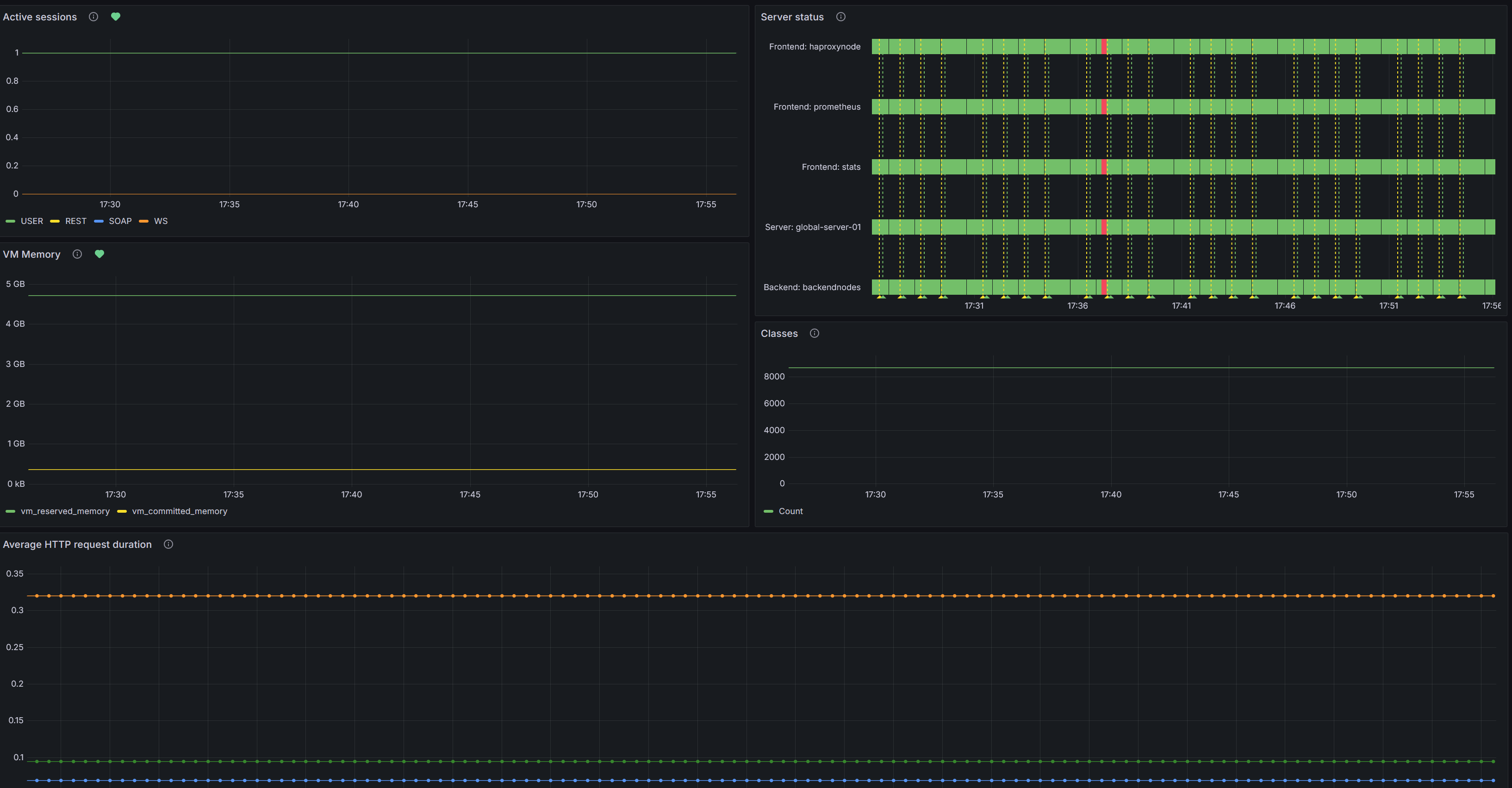
System overview
Сводный дашборд по состоянию системы и сервисов: активные сессии приложения, статус объектов HAProxy ( frontends/backends/servers), метрики виртуальной машины (reserved/committed memory, classes).
Active sessions - Активные сессии по типу - суммарное значение server_session_count по выбранному интервалу.
Server status - История статусов HAProxy: фронтенд, бэкенд в состоянии UP.
VM Memory - Память виртуальной машины приложения (JVM): Reserved vs Committed (в байтах).
Classes - Количество загруженных классов виртуальной машины (JVM).
Average HTTP request duration - Средняя длительность HTTP‑запросов (сек).
14. Добавление alering в Grafana#
Общая схема - как создать правило оповещения:
Откройте Alerting → Alert rules → New alert rule.
В секции Queries:
Выберите источник (Prometheus или Loki).
Сформируйте Query A (и при необходимости B, C…).
Нажмите Run queries и проверьте график предпросмотра.
В секции Conditions:
Добавьте Reduce (например, last, mean, sum) и при необходимости Math.
Задайте триггер: IS ABOVE/BELOW X и For.
В секции Settings:
Укажите folder (группа правил), rule name, evaluation interval (напр.
1mили30s).Настройте поведение No data и Execution error (обычно
NoData = Alertingтолько для deadman‑switch).Добавьте Labels (пример ниже).
Добавьте Annotations (короткое описание, runbook URL, link на дашборд/панель).
В Contact points создайте каналы (Email, Slack, Telegram, Webhook).
В Notification policies:
Настройте маршрутизацию по ярлыкам (
team,service,severity,env).Настройте mute timings (тихие часы/окна работ) и silences (временное подавление).
Нажмите Preview (опционально) и Save rule.
Подставьте свои переменные ($frontend, $backend, $database, $pgbouncer, $instance, $server и т. д.) и
скорректируйте пороги под вашу нагрузку.
Примечание
Ниже представлены примеры алертов. Они могут быть изменены, а также добавлены новые.
14.1. Global Logs (Loki)#
Error flood(Loki)#
Шаги настройки:
Перейти в Alerting → Alert rules → New alert rule и задать имя правила, например
Error flood.Создать два запроса Loki и одно выражение Math.
Тип: Loki, Ref ID: A
sum by (service_name) (
count_over_time({service_name=~"Global_3|Global_Scheduler|PgBouncer|PostgreSQL|HAProxy"}[1h])
)
Тип: Loki, Ref ID: B
sum by (service_name) (
count_over_time({service_name=~"Global_3|Global_Scheduler|PgBouncer|PostgreSQL|HAProxy"}[5m])
)
Тип: Math, Ref ID: C (строку пометить как Alert condition).
В поле Expression указать:
($B / $A) > 1
Объяснение: если за последние 5 минут логов больше, чем за последний час, считаем это аномалией.
Deadman (нет логов от сервиса)#
sum by(service_name) (count_over_time({service_name=~"Global_3|Global_Scheduler|PgBouncer|PostgreSQL|HAProxy"} [10m]))
Условие:
WHEN QUERY IS BELLOW OR EQUAL TO 0
14.2. HAProxy#
Отклонённые запросы#
A query:
sum(rate((haproxy_backend_requests_denied_total[$__rate_interval])))
B query:
sum(rate((haproxy_frontend_requests_denied_total[$__rate_interval])))
Math выражение:
$A + $B > 0
Бэкенд не запущен#
haproxy_backend_status{state="DOWN"}
Условие:
WHEN QUERY IS NOT EQUAL TO 0
Dead traffic (нет трафика)
rate(haproxy_backend_bytes_in_total{}[$__rate_interval])
Условие:
WHEN QUERY IS BELOW OR EQUAL TO 10
14.3. Node Exporter / System#
Высокое использование CPU#
avg(rate(node_cpu_seconds_total{job="node-exporter-global"}[5m]))
В настройке очереди перейдите на вкладку Builder и настройте фильтр по job, выбрав необходимый вам сервер.
Условие:
WHEN QUERY IS ABOVE 0.5
Нехватка свободной памяти#
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes
Условие:
WHEN QUERY IS BELOW OR EQUAL TO 0.1
Нехватка дискового пространства#
max by (instance, mountpoint) (
1 - (node_filesystem_avail_bytes{fstype!~"tmpfs|overlay"}
/ node_filesystem_size_bytes{fstype!~"tmpfs|overlay"})
)
Условие:
WHEN QUERY IS ABOVE 0.8
14.4. PgBouncer (pgSCV)#
PgBouncer недоступен#
pgbouncer_up{job="pgbouncer"}
Условие:
WHEN QUERY IS NOT EQUAL TO 1
14.5. PostgreSQL#
PostgreSQL недоступен#
postgres_up{job="pgbouncer"}
Условие:
WHEN QUERY IS NOT EQUAL TO 1
Высокая доля откатов#
sum by (datname) (rate(pg_stat_database_xact_rollback[5m]))
/ clamp_min(sum by (datname) (rate(pg_stat_database_xact_commit[5m])) + sum by (datname) (rate(pg_stat_database_xact_rollback[5m])), 1)
Условие:
WHEN QUERY IS ABOVE 0.05
14.6. System overview#
Память VM (Committed превышает порог)#
(vm_committed_memory_KB{})
/ (vm_reserved_memory_KB{})
Условие:
WHEN QUERY IS ABOVE 0.8
Активные сессии приложения#
sum by (kind) (server_session_count{server="$Server"})
Условие:
WHEN QUERY IS ABOVE <ваш_порог>
Пример панели с alerting в grafana:
15. Настройка Firewall (UFW)#
15.1. Установка и запуск#
sudo apt install ufw
sudo systemctl enable ufw --now
15.2. Базовая политика безопасности#
Применяем данные настройки на всех серверах:
sudo ufw default deny incoming
sudo ufw allow ssh
sudo ufw enable
default deny incoming- запрет всех входящих соединений по умолчанию.allow ssh- разрешение SSH-доступа.enable- активация правил.
15.3. Разрешённые порты#
Сервер мониторинга#
sudo ufw allow 9090/tcp # Prometheus
sudo ufw allow 3000/tcp # Grafana
sudo ufw allow 3100/tcp # Loki
Сервер СУБД#
sudo ufw allow 9080/tcp # Promtail
sudo ufw allow 9100/tcp # Node exporter
sudo ufw allow 9187/tcp # Postgres exporter
sudo ufw allow 9890/tcp # pgSCV
Сервер приложений#
sudo ufw allow 9080/tcp # Promtail
sudo ufw allow 8405/tcp # HAProxy telemetry
sudo ufw allow 8888/tcp # Otelcol
sudo ufw allow 9100/tcp # Node exporter
Важно
Пример приведён для тестовой среды. Также необходимо открыть порты для СУБД, сервера приложений (балансировщика). На продакшене рекомендуется ограничить доступ из вне ко всем портам мониторинга. При необходимости настроить proxy и другие меры безопасности.
15.4. Проверка состояния#
sudo ufw status verbose